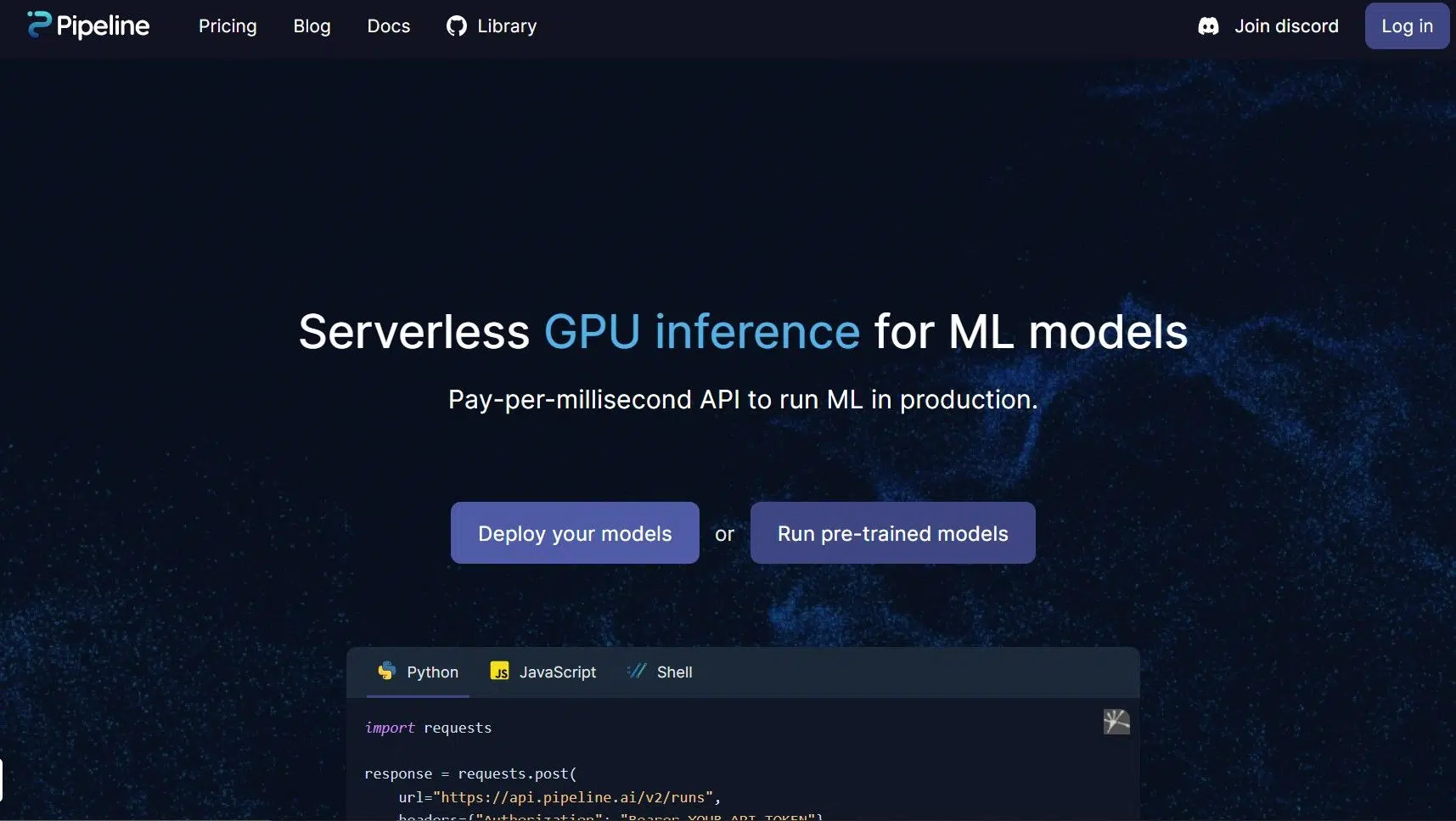
Sperimenta la facilità dell'inferenza GPU serverless per i modelli ML con la nostra API Pay-per-millisecond, che ti consente di eseguire i tuoi modelli ML in produzione senza sforzo.
La nostra piattaforma ti consente di sfruttare la potenza dell'inferenza della GPU, senza preoccuparti della gestione dell'infrastruttura o dei costi iniziali. Con un'API Pay-per-millisecond, puoi risparmiare sui costi e pagare solo per ciò che usi, rendendola una soluzione ideale per aziende di tutte le dimensioni.
Esegui i tuoi modelli ML in produzione senza soluzione di continuità, con la nostra soluzione di inferenza GPU serverless. Provalo oggi e rivoluziona il modo in cui esegui i tuoi carichi di lavoro ML!