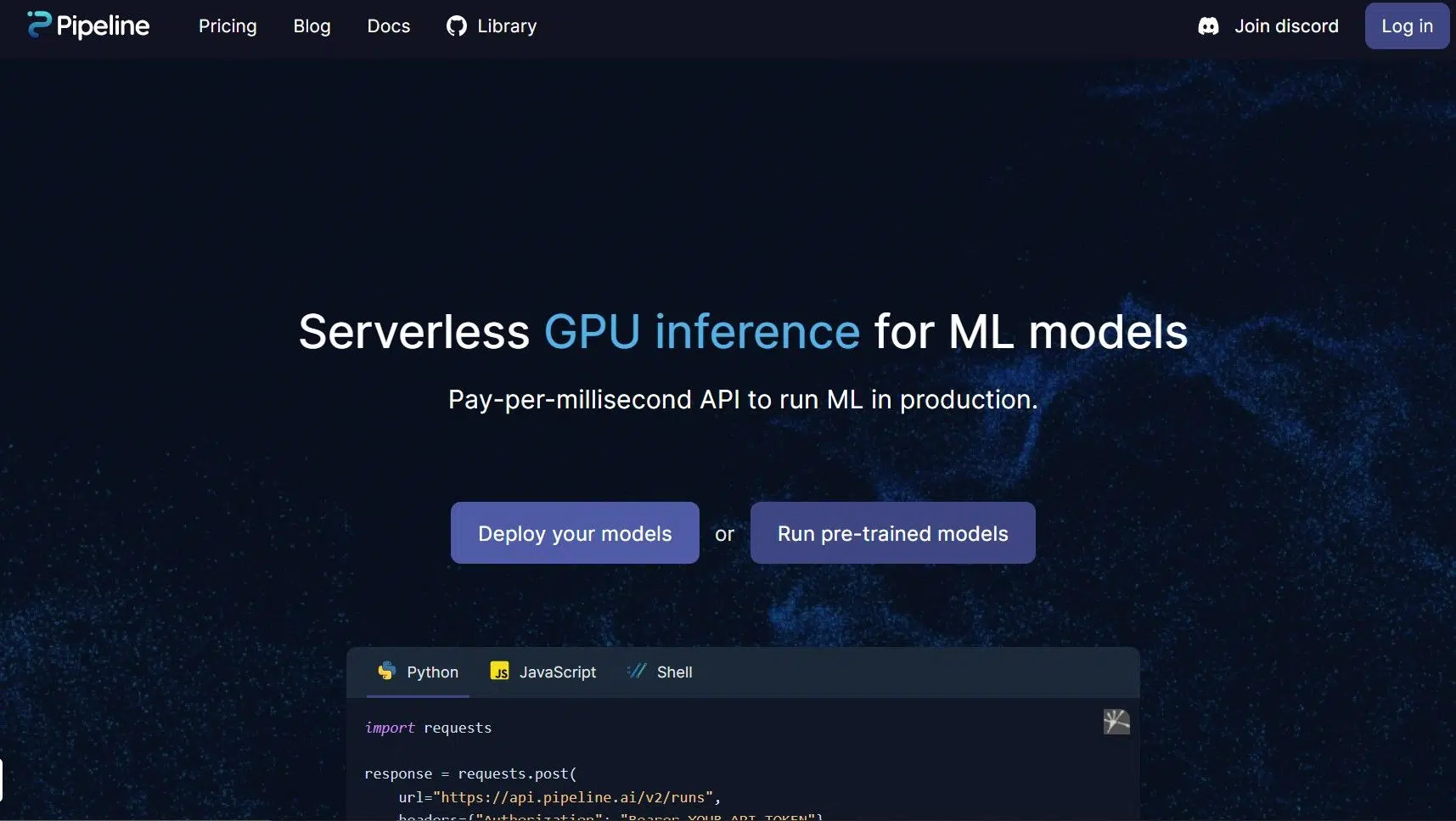
Experimente a facilidade de inferência de GPU sem servidor para modelos de ML com nossa API de pagamento por milissegundo, permitindo que você execute seus modelos de ML em produção sem esforço.
Nossa plataforma permite que você aproveite o poder da inferência de GPU, sem se preocupar com gerenciamento de infraestrutura ou custos iniciais. Com uma API de pagamento por milissegundo, você pode aproveitar a economia de custos e pagar apenas pelo que usar, tornando-a uma solução ideal para empresas de todos os tamanhos.
Execute seus modelos de ML em produção perfeitamente, com nossa solução de inferência de GPU sem servidor. Experimente hoje e revolucione a maneira como você executa suas cargas de trabalho de ML!